To be able to work with and manipulate the speech output, I need to work with Phonemes, rather than plain text. This will allow me to extend the words and 'hold a note' for longer (or sing!). But working with them would take a lot of manual work to convert them from the text of the song lyrics. So the first thing I want to do is extend my Apple/// SAM driver to help with this.
First, some background on SAM. The original SAM software came with two binary programs, SAM and RECITER.
SAM is the actual speech program that takes Phonemes as input, and outputs speech from these through the 8 bit DAC card. Phonemes are speech sounds made by the mouth. Put together these make up words or speech. The full list of Phonemes that SAM supports are available in the user manual, linked here:
SAM Owner Manual
As an example, to say "Hello There" would need the following input " /HEHLOW DHEHR" to SAM.
The other program RECITER takes plain text as input and using rule based conversion, converts these to Phonemes. It then passes the output to SAM to speak them. Reciter has a large table of rules that it uses to look at letters preceding and after to work out the Phonemes it should use. Some of these are for specific words, and some are building blocks, eg sounds for word. I just noticed it has a table entry for Atari! ".ASCII "(ATARI)=AHTAA4RI""
My Apple/// driver implementation is done as a SOS character mode driver. A character mode driver supports reading and writing character strings. Currently I have two 'sub' drivers implemented, .SAM to support Phonemes, and .RECITER to support plain text.
For both of these 'sub' drivers, you first open them. And then just write a string to them, and they will speak the string. To check for errors, you can read from these, and the error code is returned. If its 255, then all went ok. Other wise, it will return the character position in the string where the error occured. eg when an incorrect phoneme is found.
What I want to be able to do is after the .RECITER has converted the plain text to Phonemes, I want to be able to read this back. The way i will implement this is to detect when a second read occurs, then return the converted string.
I have added a variable to monitor the number of reads:
READNUM .BYTE 000 ;flag to determine number of reads after write, 0=none
Whenever a write occurs, I will clear this back to zero:
SPEAK LDA #000
STA 014FC ;disable extended indirect addressing for FB/FC
STA READNUM ;clear previous reads number
LDA EReg
Then in the READ part, i have added a check and then either return the error code for the first read
or return the converted string.
$010 LDA READNUM ;check number of previous reads
BNE RETPHONM ;yes, there has been, return converted string
;otherwise, return error code
;
;return error code
;
....
;
;return converted string containing Phonemes
;
RETPHONM LDY #00
$020 LDA INPUTBUF,Y ;read converted text from INPUTBUF
STA (BUFFER),Y ;store in read buffer
INY
CMP #ASC_CR ;if CR then this is the end of the string
BNE $020 ;no, next
TYA ;yes, ret count = index +1
LDY #00
STA (RTNCNT),Y ;actual characters read count, low byte
LDA #00
INY
STA (RTNCNT),Y ;actual characters read count, high byte
RTS
One issue with this is it will actually speak the output each time your convert. If I have time, I will come back and improve this.
I have updated the changes into my github repository for this here:
https://github.com/robjustice/Apple3SAM
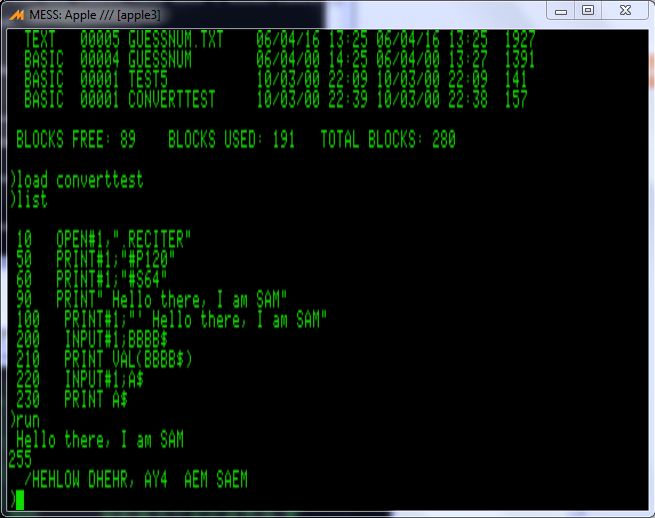
To test this out, I have updated one of my test programs to check the driver operation. The disk image is available here with the updated driver and Basic test program.
demo2.dsk
its quite simple, here is the output show the program and the output from it running in MESS:
Next step will be to add pitch statements to see if SAM can start to sing..
No comments:
Post a Comment