The idea I was thinking of was to be able to enter the music notes and the lyrics either directly into the basic program, or enter them as a text file and have the program read it. I think I'll use this as a good easy song to start with. :-)

Then have a file something like this, notes, then duration, and the lyrics lined up possibly to get the timing.
c.5 c.5 d1 c1 f1 e2 c.5 c.5 d1 c1 f1 e2
Hap-py birth-day to you Hap-py birth-day to you
I need to try and work out some ways to transfer the music notes to the speech to bring the tune into it. And play with some of the other features of SAM to see what adds to this. First thing was to enter the text and convert using the new function on my driver. The first line converted to phonemes ends up like this.
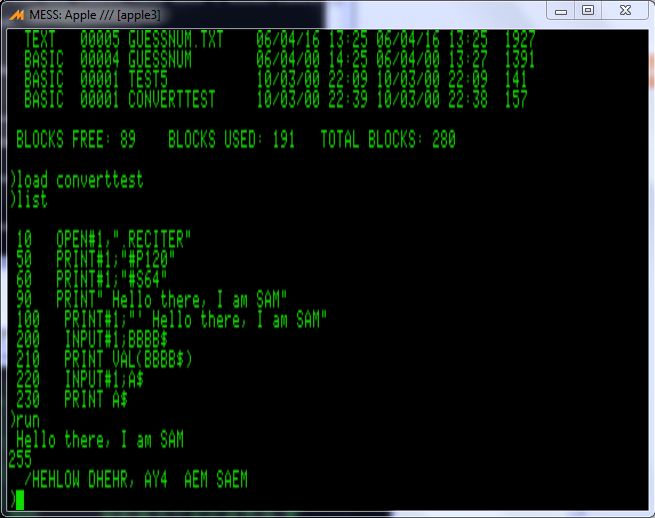
/HAEPIY BERTH DEY5 TUX YUW
SAM supports setting the pitch, the standard pitch used is 120 in the examples, so the first thought was to make this C, and then add 10 for each note. ie D becomes 110, E = 120, and so on. rolled out, it becomes like this.
"#P120" (C)
"/HAE"
"#P120" (C)
"PIY"
"#P130" (D)
" BERTH"
"#P120" (C)
" DEY5"
"#P150" (F)
" TUX"
"#P140" (E)
" YUW"
Well, here is how that sounds, not to good at all.
Happy1.mp3
Now remember the opening line of the blog, a quick look at the SAM manual and it looks like the pitch is the other way around, smaller value is higher pitch.
PITCH
00-20 impractical
20-30 very high
30-40 high
40-50 high normal
50-70 normal
70-80 low normal
80-90 low
90-255 very low
default = 64
A quick swap around and this was the modified test program:

and this was the result. Still not to good.
Happy2.mp3
SAM supports adding a stress value after the phoneme to add some expression. From the manual:
1 = very emotional stress
2 = very emphatic stress
3 = rather strong stress
4 = ordinary stress
5 = tight stress
6 = neutral (no pitch change) stress
7 = pitch-dropping stress
8 = extreme pitch-dropping stress
I then added a value of 5, need to have a play with these more, they might be quite useful.
This was the modified test program with an arbitrary stress value after the last phoneme:

and this was the result. Not to sure if this is better, I think it is improving.
Happy3.mp3
Then the next thing was to extend the words, based on timing. I did this by just repeating the phonemes. Although the last word 'you' should probably be extended more, but it does not sound to good like that. Need to try some other ideas for it.
This is the test program with these changes:

and here is the result, its starting to get there!
Happy4.mp3
I need to play some more with this, but I have some ideas now on how to translate from the music/lyrics to SAM.